Avro vs Jackson vs Gson serialisation on Apache Flink
This article describes a research on deserialising data on Apache Flink when different serialisation engines were used.
TL;DR: Those are the findings

Methodology
The test consisted in having messages made of nested data, into a max depth of 4, for instance root.category.subcategory.property = ["item"] and running a producer, adding random 1000000 messages into kafka and, then, enabling the Apache Flink application to read from the kafka topic the whole lot at once, deserialising message per message on the source operator and measuring the deserialisation process individually and in total.
Each engine had its own implementation of AbstractDesserializationSchema where, inside the deserialise method, we gathered the time spent in the deserialisation operation for each item as shown beneath:

The overall measurement was done over the whole stream as shown in the graph beneath:

Each engine was tested by running the deserialisation five consecutive times on a Intel i9 MacBookPro with 32GB Ram. Each run consisted of the same load of 1000000 (one million) messages pre-written on a Kafka topic by a generic producer. The records were first written to Kafka and, after the write is over, the Flink application started and consumed the whole topic before writing the overall times. The log written was done asynchronously and did not impact the overall measurements.
Here are the results for the five runs for each engine statistics:
Avro

Jackson

GSON

Conclusion
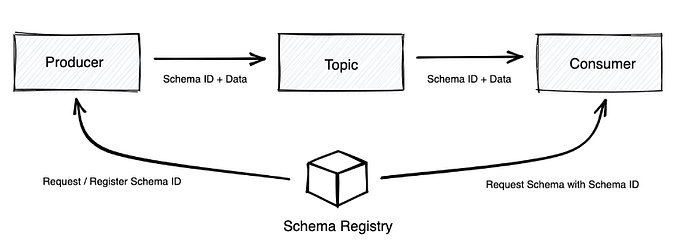
As seen on the above tables, the results shows that AVRO has a faster deserialisation engine and that, also, it provides smaller message sizes. BUT, there's a caveat: AVRO requires a schema and, if you're working within a distributed environment where, for instance, a producer and a consumer needs to use the same schema for serialising and deserialising, there's a need for a schema registry and, with it, the overall complexity of the pipeline increases. There are already some schema registry as a service to overcome this problem but this is not on the scope of this article.
If you want to learn more about this experiment, please, feel free to reach out to me and we can discuss it further. I'm working on a docker setup where it'll be possible to run this experiment over and over again in a controlled way.